Get Started
Introduction
The aim of this documentation is to describe how to use the Data Migrator to build a database over its architectural items and to populate it with data.
This tool consumes metadata artifacts that could be provided from:
- Result artifacts coming from Analyzer step when parses DDL DB2
- Result artifacts coming from Analyzer step when parses PF and LF files in AS400 projects
The Data Migrator is a standalone application. It is provided as Linux or Window installer and is launched through a command line.
The Data Migrator enables to work with several kinds of database :
- POSTGRESQL
- MSSQL
- ORACLE
POSTGRESQL
Nothing in particular.
To bulk-load data, Bluage Data Migrator uses POSTGRESQL provided copy statement.
MSSQL
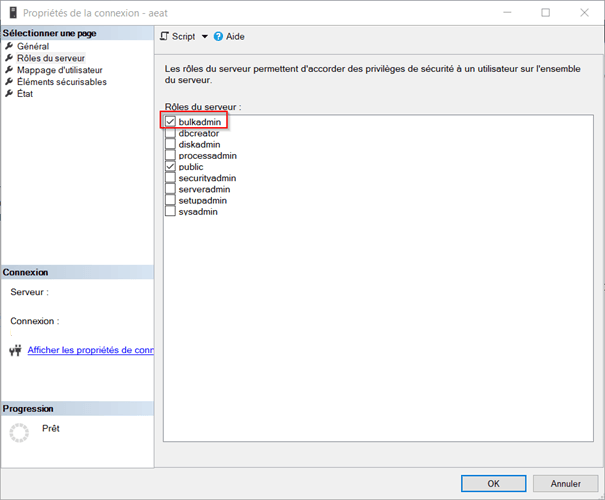
To bulk-load data, Data Migrator uses MSSQL provided BULK INSERT statement. To enable bulk-loading, you have to specify it, for example, with Microsoft SQL Server Management Studio:
ORACLE
To bulk-load data, Data Migrator uses sqlldr tool which must be installed on your machine with a well-defined path.
How it works
Data Migrator tool connects to databases specified in the configuration steps and, for POSTRESQL only, drops and creates the database.
The tool applies all the enabled action steps specified.
For the creation or deletion step, it executes scripts from the sql files included in the input directory of the step.
For the conversion step, it converts the data included in the input directory of the step and put the results in the output directory of the step.
For the data loading step, it loads data included in the input directory of the step to database.
During the data loading step, considered table to fill are taken from sqlModel.json table list or collected from the sql files if sqlModel.json is missing. Under the designed data folder (dataFolder), data files must be stored under folder named as the table name.